DiT: U-Net 버리고 Transformer 쓰니까 Scaling Law가 적용됐다 (Sora 기반기술)
U-Net은 크기 키워도 성능 향상이 수확체감. DiT는 모델이 클수록 일관되게 좋아집니다. Sora의 기반이 된 아키텍처 완전 분석.

DiT: Diffusion Transformer, U-Net을 넘어선 새로운 패러다임
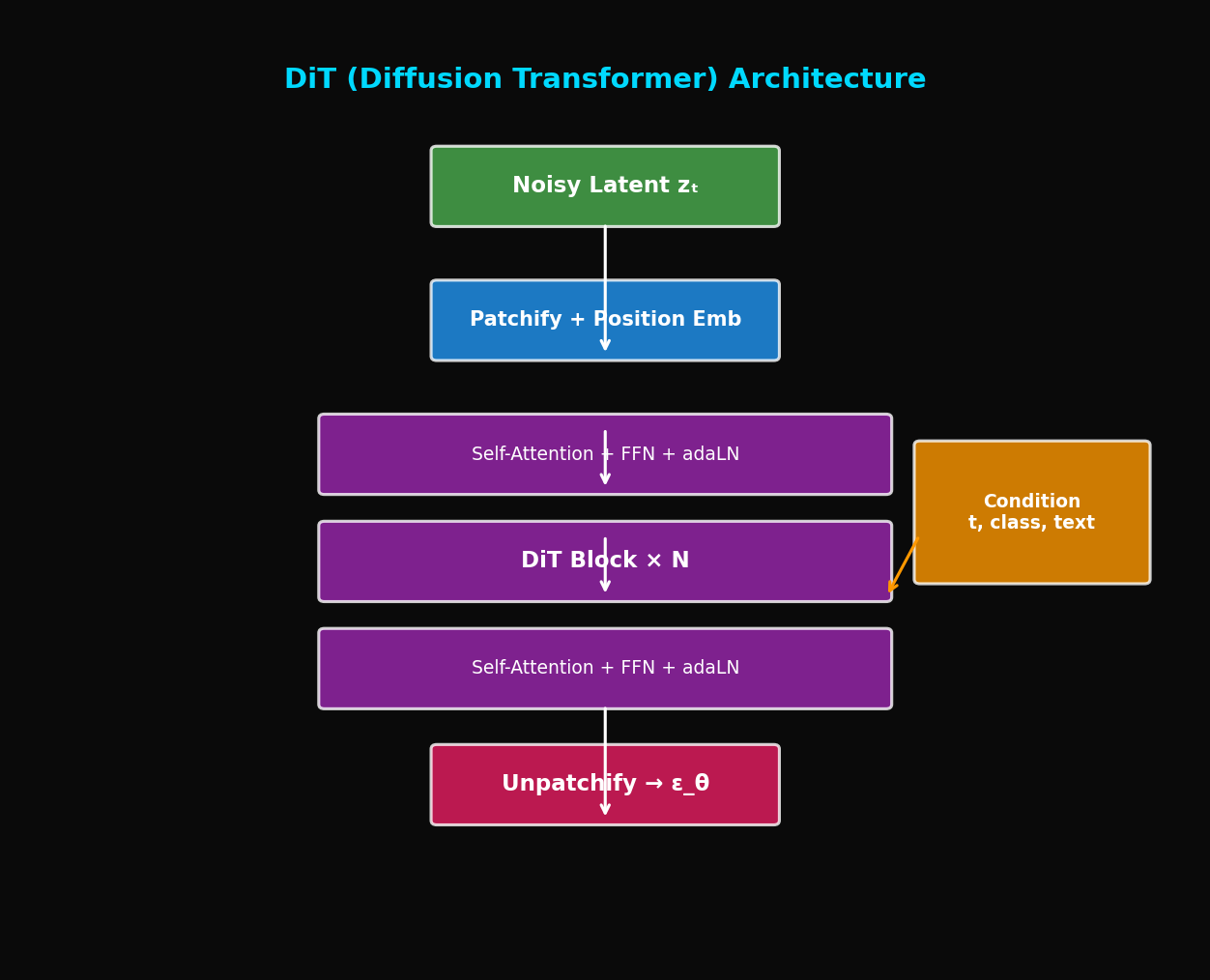
TL;DR: DiT는 Diffusion 모델의 backbone을 U-Net에서 Vision Transformer로 교체합니다. Scaling law가 적용되어 모델이 커질수록 성능이 일관되게 향상됩니다. Sora의 기반 기술입니다.
1. U-Net의 한계
1.1 왜 U-Net이었나?
관련 포스트

Models & Algorithms
TurboQuant 실전 — llama.cpp와 HuggingFace에서 KV Cache 압축하기
llama.cpp turbo3 빌드, HuggingFace 통합, 메모리 계산기, 최적 설정 가이드. 70B 모델 536K 컨텍스트 실현.

Models & Algorithms
TurboQuant 완전 해부 — Google의 KV Cache 극한 압축 알고리즘
PolarQuant + Lloyd-Max로 KV Cache를 3비트까지 압축. 리트레이닝 없이 4.6배 메모리 절약, 정확도 손실 제로.

Models & Algorithms
Qwen 3.5 파인튜닝 실전 가이드 — LoRA로 나만의 모델 만들기
Qwen 3.5를 LoRA/QLoRA로 파인튜닝하는 전 과정을 다룹니다. 8GB GPU에서도 가능한 QLoRA 설정부터 Unsloth 최적화, GGUF 변환, Ollama 배포까지.