Why GPT-4o Is So Fast: The Critical Difference Between Multimodal and Omni Models
A token-level analysis comparing the pipeline approach (STT→LLM→TTS) text bottleneck with native omni model token fusion. Explains why GPT-4o and MiniCPM-o are fundamentally faster.

Why GPT-4o Is So Fast: The Critical Difference Between Multimodal and Omni Models
When GPT-4o launched, what surprised most people wasn't its performance. It was the speed. Ask it something by voice, and it responds in near real-time with emotion in its voice. It felt fundamentally different from every voice AI before it.
And then MiniCPM-o 4.5 matched that GPT-4o-level performance with just 9B parameters. How?
The answer lies in the "Omni architecture." More precisely, it comes down to how different modalities of data are tokenized and mixed inside a single model.
In this article, we dissect the difference between the pipeline approach and the native Omni approach at the token level.
The Pipeline Approach: Why It's Slow and Awkward
Before 2024, most "voice AI" systems looked like this:
User speech → [Whisper] → text → [LLM] → text → [TTS] → AI speechThree independent models running sequentially. Let's look at what happens at each stage.
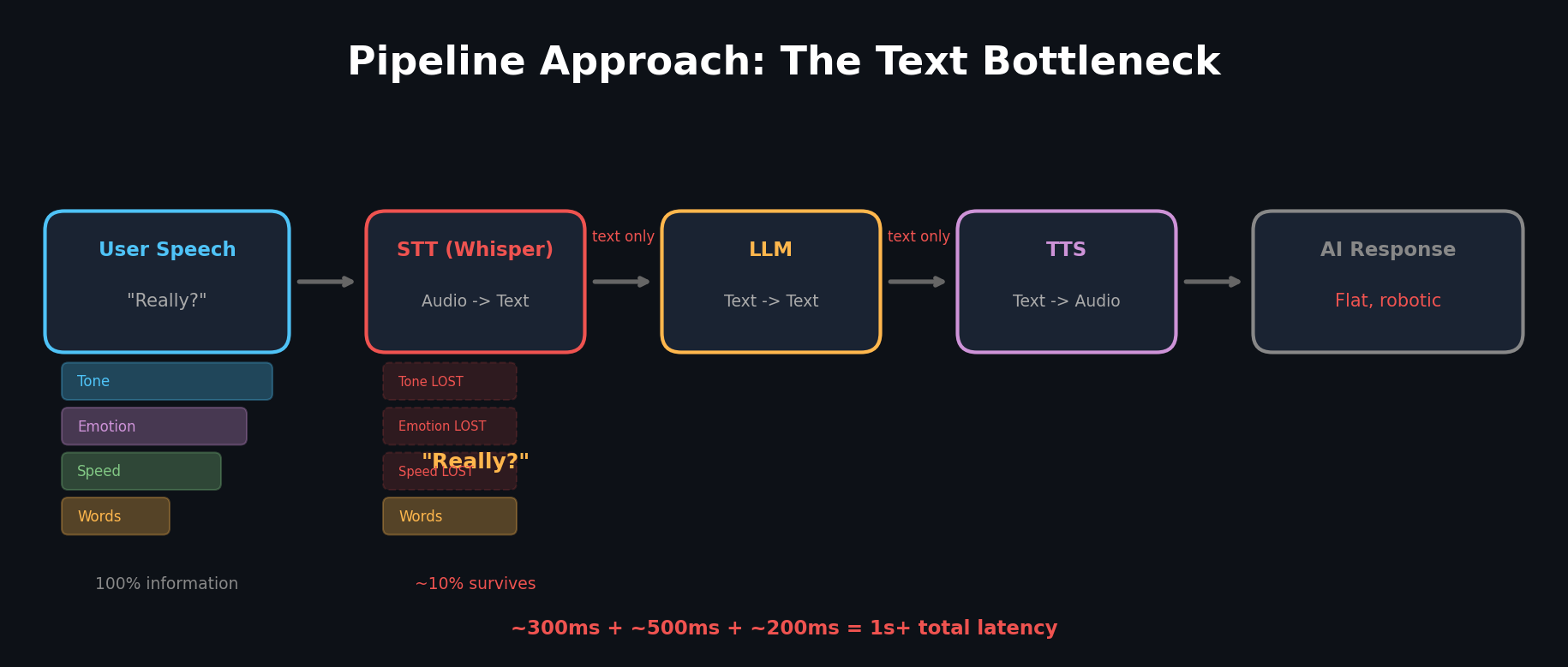
Stage 1: Speech → Text (STT)
An STT model like Whisper converts speech to text. This is where the first information loss occurs.
Say the user says "Really?" That single word carries rich information:
- Tone of surprise (pitch rising)
- A hint of skepticism (specific intonation pattern)
- Speaking speed (fast = excitement, slow = doubt)
STT compresses all of this into the text string "Really?" — seven characters. Tone, emotion, speed, speaker characteristics — all gone.
Stage 2: Text → Text (LLM)
The LLM receives only the text "Really?" It can't distinguish whether it was said in surprise, sarcastically, or with genuine curiosity. It can only guess from context.
Stage 3: Text → Speech (TTS)
TTS reads aloud the text generated by the LLM. But TTS also has no information about what emotion to convey. The result: flat, robotic speech.
The Fundamental Problem: The Text Bottleneck
The root issue is that text is a bottleneck.
In human conversation, the actual words convey only a fraction of the total information. Psychology research suggests that nonverbal elements (tone, speed, facial expressions) account for over 90% of emotional communication.
In the pipeline, this 90% evaporates at the STT stage.
Then there's the latency problem. Three models running sequentially:
- STT: ~300ms
- LLM: ~500ms (to first token)
- TTS: ~200ms
- Total: 1 second or more
In natural conversation, a 1-second delay feels deeply unnatural. Think about how even a 0.5-second delay on a phone call makes you say "Hello? Can you hear me?"
The Omni Approach: Everything Becomes Tokens
Let's see how GPT-4o and MiniCPM-o solve this.
The core idea is simple: convert text, speech, and images all into the same format of tokens, then process them together in a single transformer.

User speech + video → [Unified Encoder] → mixed token sequence → [Single LLM] → mixed tokens → [Decoder] → AI speech + textThe critical difference from the pipeline: there's no intermediate step of compressing everything into text.
How Each Modality Gets Tokenized
Let's get specific about how omni models turn different types of data into "tokens."
Text Tokenization: Nothing New Here
Text is tokenized with BPE (Byte Pair Encoding) or SentencePiece. Words get split into subword tokens, each mapped to an integer ID. No innovation here.
Image Tokenization: Patches to Embeddings
Images are processed by ViT (Vision Transformer) family encoders. MiniCPM-o uses SigLip2.
The process:
- Split the image into small patches (e.g., 14x14 pixels)
- Vectorize each patch via linear projection
- Add position embeddings
- Pass through transformer encoder → generate visual tokens
Key insight: higher resolution means more patches, which means more visual tokens. SigLip2 processing up to 1.8M pixels means it generates highly detailed visual tokens. This is precisely why OCR performance is so strong.
Audio Tokenization: This Is Where It Gets Interesting
There are two main approaches to audio tokenization.
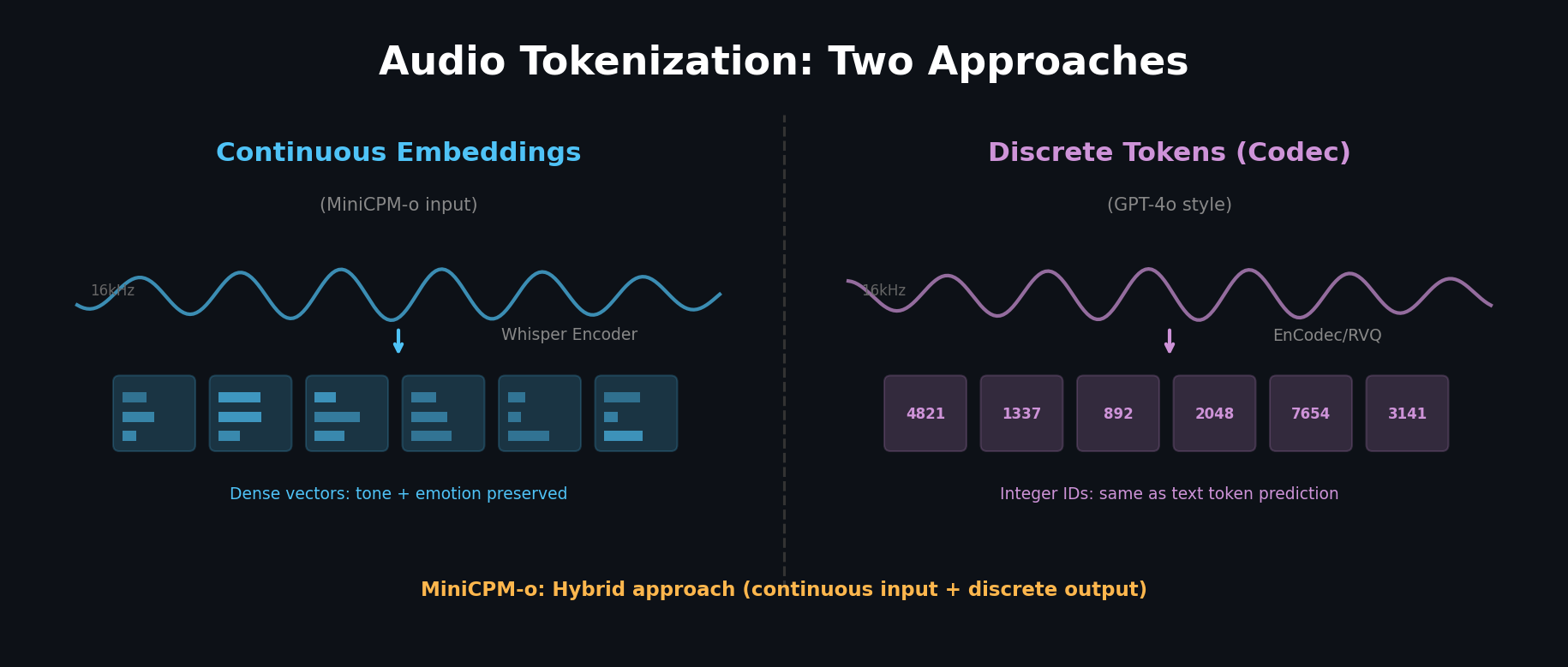
Method 1: Continuous Embeddings
Use an encoder like Whisper to convert audio into a continuous vector sequence.
- 16kHz audio → mel spectrogram → encoder → embedding sequence
- Advantage: rich speech information (tone, emotion, speed) preserved in the vectors
- This is what MiniCPM-o uses for speech input
Method 2: Discrete Tokens
Use audio codecs (EnCodec, SoundStream, etc.) to convert speech into a discrete token sequence.
- 16kHz audio → codec encoder → discrete token ID sequence
- Uses RVQ (Residual Vector Quantization) with multiple codebook levels
- Advantage: next-token prediction works the same way as for text
- This is the approach GPT-4o is believed to use
MiniCPM-o combines both approaches:
- Input: Whisper's continuous embeddings
- Output: Streaming Flow Matching Decoder + Interleaved Speech Token Decoder
- This hybrid approach enables Full-Duplex (simultaneous input/output)
When Tokens Meet Inside the LLM
This is the most important part. How are tokens from different modalities processed inside a single transformer?
[visual_token1][visual_token2]...[visual_tokenN][audio_token1][audio_token2]...[text_token1][text_token2]...This mixed sequence passes through the transformer's self-attention as a whole. At this point:
- Audio tokens can attend to visual tokens
- Text tokens can attend to audio tokens
- All modalities directly reference each other
This is impossible in a pipeline. When you say "describe this image" by voice, an omni model simultaneously references both your vocal tone and the image content to generate its response.
Dimension Alignment: Making All Tokens Speak the Same Language
Tokens from different encoders may have different dimensions. SigLip2's output dimension, Whisper's output dimension, and Qwen3's embedding dimension could all differ.
Projection layers handle this alignment:
Visual tokens (SigLip2 output) → Linear Projection → LLM dimension
Audio tokens (Whisper output) → Linear Projection → LLM dimension
Text tokens → Embedding table → LLM dimensionThis projection is crucial. Once tokens from different modalities are mapped into the same vector space, the transformer processes them without distinction. It's similar to how Korean and English can be understood without translation once they're mapped into the same embedding space.
Full-Duplex: Listening and Speaking Simultaneously
MiniCPM-o's Full-Duplex capability is the pinnacle of this tokenization architecture.
Traditional voice AI is half-duplex. VAD (Voice Activity Detection) senses when the user is speaking, and the system responds only after the user stops. No interruptions possible.
In Full-Duplex:
- User speech is tokenized in real-time and fed into the model
- The model generates response tokens while simultaneously receiving new input tokens
- When the user interrupts, new input tokens are immediately reflected through the model's attention
- The model recognizes "oh, the user interrupted" and stops or adjusts its response
This works because both input and output exist in the same token space. In a pipeline, STT must fully complete before the LLM can start, making Full-Duplex structurally impossible.
Why 9B Is Enough
"But how can 9B match GPT-4o?" — a fair question.
1. The Power of Specialist Encoders
MiniCPM-o's 9B refers to the LLM parameters alone. On top of this, pretrained specialist encoders like SigLip2 (vision) and Whisper (speech) are added. These are models already trained on hundreds of millions of data points in their respective domains.
The LLM only needs to "think." SigLip2 handles seeing, Whisper handles hearing. 9B of reasoning capacity is enough to synthesize this information.
2. Token Efficiency
In the pipeline approach, speech information is compressed into text, losing information. In the omni approach, rich tokens flow directly into the model, allowing the same parameters to leverage more information.
An analogy: the pipeline analyzes a full-color photo after converting it to black and white. Omni analyzes the full-color original.
3. End-to-End Optimization
Each module in a pipeline is trained independently. The STT is optimized only for "converting speech to accurate text" — it doesn't know what the LLM needs.
In an omni model, the entire system is optimized end-to-end. The speech encoder learns to tokenize speech "in a form the LLM can best understand." This alignment enables high performance even in smaller models.
What This Means in Practice
Secure Data Processing
Consider a scenario where you're verbally discussing a contract while simultaneously analyzing the document image.
Pipeline: voice → external STT API → text → external LLM API → external TTS API. Sensitive contract details pass through multiple external services.
Omni model: process speech and document image locally in one pass. Data never leaves the device. MiniCPM-o's 11GB VRAM is sufficient.
Real-Time Interpretation
In interpretation, a 0.5-second difference changes the flow of conversation.
Pipeline: speech recognition (300ms) + translation (500ms) + speech synthesis (200ms) = minimum 1 second delay
Omni model: speech tokens → immediately translated speech token output. TTFT 0.6 seconds
Multimodal Analysis
"I see something unusual in this X-ray, can you explain it?" — requesting by voice while showing the image.
In a pipeline, speech and image are processed separately. In an omni model, the "something unusual" audio tokens and X-ray image tokens connect directly through attention. The model even reads the "where is it unusual?" context from your vocal tone.
Current Limitations and Future Directions
Let's be honest about current limitations.
Token Count Explosion
High-resolution image + long audio input simultaneously causes token counts to spike dramatically. Visual tokens from a 1.8M pixel image plus audio tokens from 30 seconds of speech can total thousands. Since transformer self-attention scales quadratically with token count, this can become a bottleneck.
Cross-Modal Interference
Processing all modalities in one transformer can cause "interference" where training on one modality degrades performance on another. Research into MoE (Mixture of Experts) and modality-specific adapters is ongoing to mitigate this.
Training Data
Omni model training requires modality-aligned data — for example, "(while looking at this image) explain it like this" with image, speech, and text simultaneously present. Such data is far scarcer than text-only data.
Summary
| Aspect | Pipeline | Omni (Native) |
|---|---|---|
| Information Preservation | Compressed to text, emotion/tone lost | Original information preserved |
| Latency | Sequential modules (~1s+) | Single model (~0.6s) |
| Full-Duplex | Structurally impossible | Possible |
| Cross-Modal Reasoning | Limited | Direct reference via attention |
| Security | Multiple external API dependencies | Local processing possible |
| Model Size | Sum of 3 models | Single unified model |
An omni model isn't simply "a model that handles multiple modalities." It's a model that fuses tokens from different senses in a unified space.
GPT-4o is fast not because "the servers are powerful," but because the architecture itself is designed to eliminate latency. And MiniCPM-o matching this with 9B parameters is proof that the power of this architecture transcends model size.
Links
- MiniCPM-o 4.5 deep dive: On-Device GPT-4o Has Arrived?
- HuggingFace: openbmb/MiniCPM-o-4_5
- GitHub: OpenBMB/MiniCPM-o
Subscribe to Newsletter
Related Posts

Breaking the Reversal Curse with Identity Bridges — the ICML 2026 fix that shouldn't work but does
LLMs trained on "Alice's husband is Bob" famously fail on "Bob's wife is?" — the reversal curse. A new ICML 2026 paper fixes it by adding one weird kind of self-referential example to the training set. The naive version doesn't work; the right version does.

Inside Google COSMO — The New Architecture of On-Device AI Agents
Deep-dive into COSMO, Google's next-gen AI assistant accidentally leaked before I/O 2026. Full breakdown of the 3-mode architecture: Gemini Nano + PI server + Hybrid routing.

Gemma 4 — Google's Open Model That Rewrites the Rules
First Gemma model under Apache 2.0. Arena #3 overall. 31B Dense, 26B MoE (3.8B active), E4B/E2B edge models. AIME 89.2%, Codeforces ELO 2150, 256K context, multimodal.