Gemma 4 — Google's Open Model That Rewrites the Rules
First Gemma model under Apache 2.0. Arena #3 overall. 31B Dense, 26B MoE (3.8B active), E4B/E2B edge models. AIME 89.2%, Codeforces ELO 2150, 256K context, multimodal.
Gemma 4: Google's Open Model That Rewrites the Rules
On April 2, 2026, Google released Gemma 4 — the first Gemma model under the Apache 2.0 license — and it immediately landed at #3 on the Chatbot Arena leaderboard, setting a new standard for open models.
A 31B parameter model competing with GPT-4o and Claude 3.5 Sonnet. A 3.8B active-parameter MoE model running on a single consumer GPU. Edge models that fit in under 1.5GB of RAM. Four model variants, 256K context, multimodal (text + image + audio). Let's break it all down.
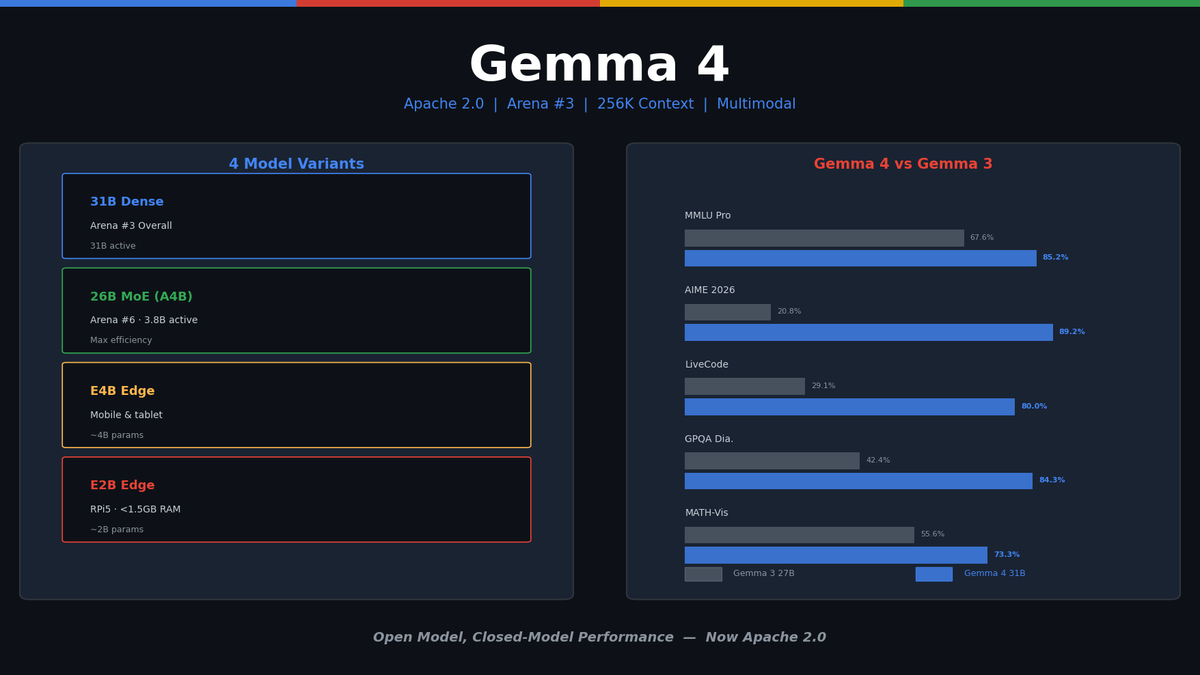
The Gemma 4 Lineup
| Model | Parameters | Active Params | Arena Rank | Use Case |
|---|---|---|---|---|
| Gemma 4 31B | 31B (Dense) | 31B | #3 Overall | Peak performance, server/cloud |
| Gemma 4 26B (A4B) | 26B (MoE) | 3.8B | #6 Overall | Maximum efficiency, local GPU |
| Gemma 4 E4B | ~4B | ~4B | — | Mobile/edge |
| Gemma 4 E2B | ~2B | ~2B | — | Ultra-light edge, IoT |
Key Points
- Apache 2.0: First for the Gemma series. Full commercial use, modification, and redistribution. A major shift from Gemma 3's restrictive license.
- MoE Architecture: The 26B model activates only 3.8B of its 26B parameters during inference. Memory and compute costs drop dramatically.
- 256K Context: All models support 256K tokens. Analyze entire codebases and long documents.
- Multimodal: Text, image, and audio input. Native aspect-ratio handling for images.
Benchmarks: How Much Better Than Gemma 3?
Gemma 4 31B vs Gemma 3 27B:
| Benchmark | Gemma 3 27B | Gemma 4 31B | Change |
|---|---|---|---|
| MMLU Pro | 67.6% | 85.2% | +17.6p |
| AIME 2026 | 20.8% | 89.2% | +68.4p |
| LiveCodeBench v6 | 29.1% | 80.0% | +50.9p |
| Codeforces ELO | 1154 | 2150 | +996 |
| GPQA Diamond | 42.4% | 84.3% | +41.9p |
| MATH-Vision | 55.6% | 73.3% | +17.7p |
89.2% on AIME 2026 is staggering. Gemma 3 scored 20.8%. This isn't an incremental improvement — it's a generational leap in mathematical reasoning.
Codeforces ELO 2150 puts it at human Master level. Best-in-class among open models for competitive programming.
Architecture: What Changed
Dense Model (31B)
Standard Transformer architecture with several optimizations:
- Hybrid Attention: Sliding Window + Global Attention. Efficiently handles both local and long-range context.
- GQA (Grouped Query Attention): Groups Key-Value heads to reduce memory footprint.
- Per-layer Embeddings: Independent embeddings per layer for richer representations.
- QK/V Normalization: Normalizes queries, keys, and values for training stability.
- Proportional RoPE: Proportional positional encoding that maintains performance at long contexts.
- Softcapping: Bounds logit values to prevent extreme probability distributions.
MoE Model (26B/A4B)
Mixture-of-Experts with 26B total parameters, 3.8B active during inference:
- Expert layers placed independently between dense layers
- Router selects appropriate experts per input token
- Extreme parameter efficiency — Arena #6 with just 3.8B active parameters is unprecedented
Edge Models (E4B, E2B)
- E2B runs in under 1.5GB of memory
- Raspberry Pi 5: 133 tok/s prefill, 7.6 tok/s decode
- Designed for mobile, IoT, and embedded devices
Competitive Landscape
vs Qwen 3.5 (Alibaba)
| Gemma 4 31B | Qwen 3.5 32B | |
|---|---|---|
| License | Apache 2.0 | Apache 2.0 |
| Arena Rank | #3 | ~#8 |
| MMLU Pro | 85.2% | ~82% |
| Coding | Codeforces 2150 | ~1900 |
| Multimodal | Text+Image+Audio | Text+Image |
| Edge Models | E2B (1.5GB) | None |
Gemma 4 leads in benchmarks, edge lineup, and audio support.
vs Llama 4 (Meta)
| Gemma 4 31B | Llama 4 Scout | |
|---|---|---|
| License | Apache 2.0 | Llama License |
| Architecture | Dense | MoE (17B active/109B) |
| Arena Rank | #3 | #4 |
| Context | 256K | 10M |
| Edge Models | E2B/E4B | None |
Llama 4's 10M token context is impressive, but Gemma 4 wins on Arena ranking and licensing. Meta's Llama License requires separate licensing for 700M+ monthly users and prohibits using outputs to train competing models.
Ecosystem: Day-One Support
Major inference frameworks supported from launch:
- llama.cpp: GGUF quantized models available immediately
- Ollama:
ollama run gemma4— one command to run locally - vLLM: Production serving optimized
- LM Studio: Local GUI-based execution
- transformers.js: Run in the browser
- Google AI Studio: Free API access
Running Locally with Ollama
# 31B Dense model
ollama run gemma4:31b
# 26B MoE model (lightweight)
ollama run gemma4:26b
# Edge model
ollama run gemma4:e2bFine-Tuning: LoRA Customization
Gemma 4 supports 140+ languages out of the box, but domain or style-specific tasks benefit from fine-tuning.
Thanks to Gemma 4's Apache 2.0 license, commercial distribution of fine-tuned models is fully unrestricted — the biggest licensing change from previous Gemma versions.
MoE models require a different LoRA approach than Dense — which Expert layers to target, why the Router stays frozen, how to adjust learning rates. We've put together a full series covering theory through production code.
LoRA Fine-Tuning Series — From Theory to Gemma 4 MoE in Practice
Parts 1-3 cover LoRA theory, QLoRA, and evaluation/deployment. Part 4 applies LoRA to Gemma 4 MoE Expert layers. Includes hands-on notebooks.
Who Should Use What?
Gemma 4 31B (Dense):
- Production services demanding peak performance
- RAG pipelines, code generation, complex reasoning
- GPU server environments (A100/H100)
Gemma 4 26B/A4B (MoE):
- High performance on local GPUs
- Best model you can run on a single RTX 4090
- Maximum performance-per-dollar
Gemma 4 E4B/E2B (Edge):
- Mobile app integration
- IoT/embedded systems
- Offline-capable environments
Conclusion
Gemma 4 matters for three reasons:
- Apache 2.0: A new licensing standard for open models. Use, modify, and distribute commercially with zero restrictions.
- Performance: Arena #3 proves open models can compete head-to-head with closed ones.
- Edge lineup: Models running in under 1.5GB on a Raspberry Pi — the practical start of on-device AI.
The MoE model (26B/A4B) is particularly impressive. Arena #6 with only 3.8B active parameters sets a new benchmark for parameter efficiency. For developers wanting to run powerful LLMs locally, this is the most compelling option available today.
References
Related Posts

Self-Evolving AI Agents — The New Paradigm of 2026
GenericAgent, Evolver, Open Agents — comparing 3 self-evolving agent frameworks that learn, adapt, and grow without human coding.

Build Your Own LLM Knowledge Base — A Karpathy-Style Knowledge System
Complete guide to building a permanent personal knowledge system with Obsidian + Claude Code. Wiki + Memory dual-axis architecture.

Why Karpathy's CLAUDE.md Got 48K Stars — And How to Write Your Own
One markdown file raised AI coding accuracy from 65% to 94%. Analyzing Karpathy's 4 rules and practical writing guide.