Production Survival Guide for Vibe Coders
5 Non-Negotiable Standards for Enterprise Deployment
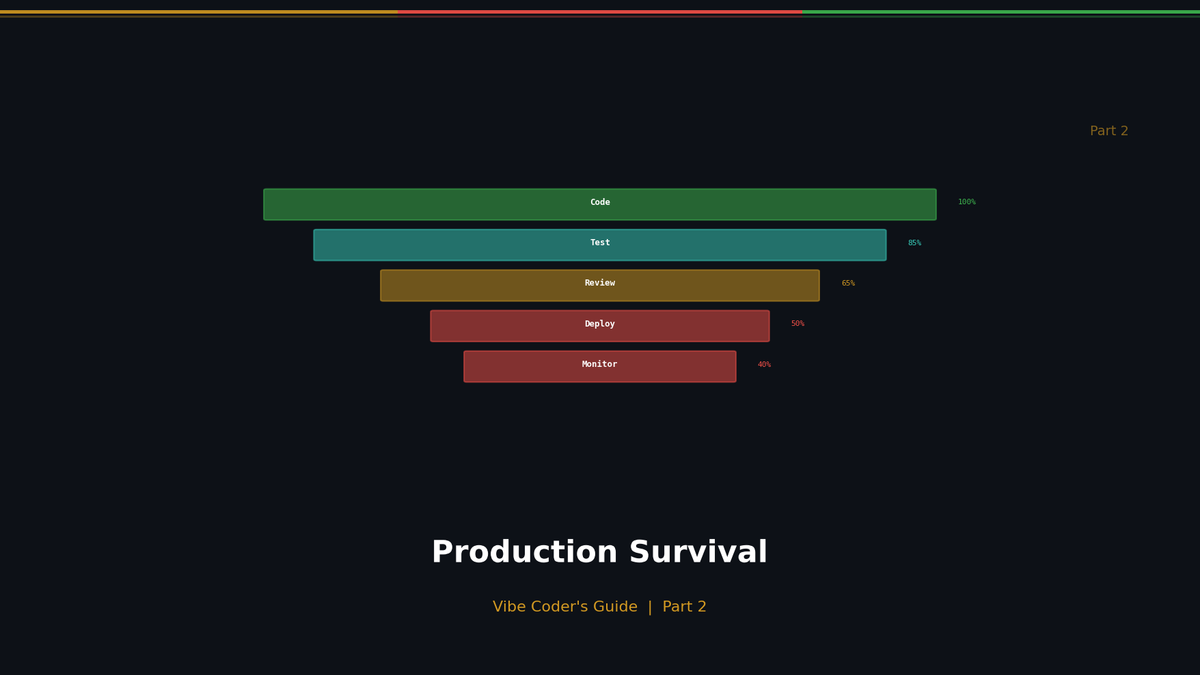
Production Survival Guide for Vibe Coders
5 Non-Negotiable Standards for Enterprise Deployment
In the age of vibe coding, anyone can deploy an app. But preventing post-launch disasters isn't about coding skills—it's about engineering standards.
Just clicking the Vercel deploy button? Here are the 5 safety measures that enterprises never skip before launching a service.
Step 1: Visibility (Logging & Monitoring)
Related Posts
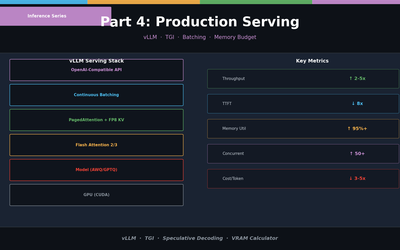
LLM Inference Optimization Part 4 — Production Serving
Production deployment with vLLM and TGI. Continuous Batching, Speculative Decoding, memory budget design, and throughput benchmarks.
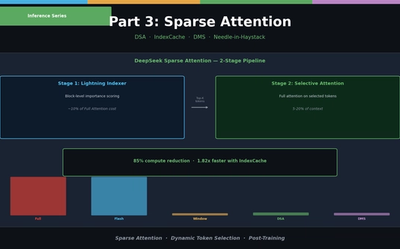
LLM Inference Optimization Part 3 — Sparse Attention in Practice
Sliding Window, Sink Attention, DeepSeek DSA, IndexCache, and Nvidia DMS. From dynamic token selection to Needle-in-a-Haystack evaluation.
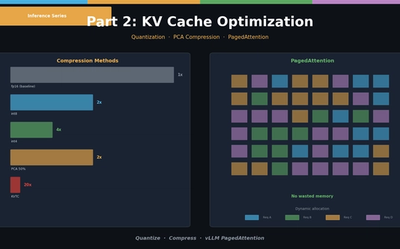
LLM Inference Optimization Part 2 — KV Cache Optimization
KV Cache quantization (int8/int4), PCA compression (KVTC), and PagedAttention (vLLM). Hands-on memory reduction code and scenario-based configuration guide.