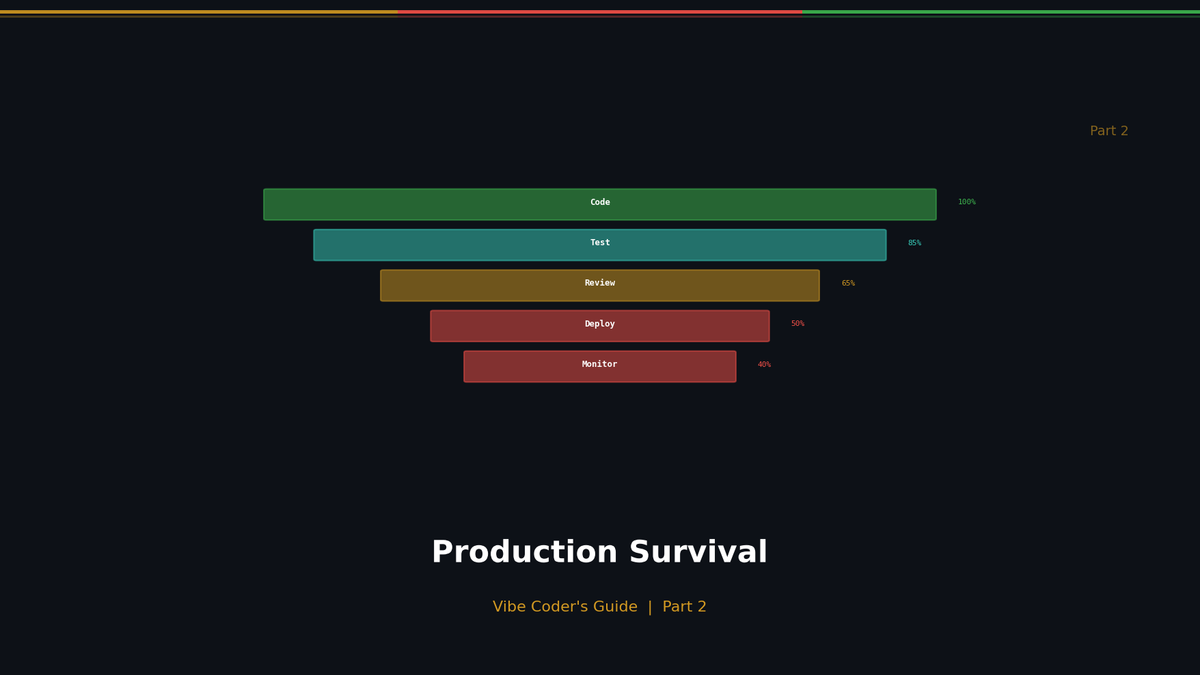
바이브코더를 위한 프로덕션 생존 가이드
기업 배포에서 '절대' 생략하지 않는 5단계 표준
바이브코더를 위한 프로덕션 생존 가이드
기업 배포에서 '절대' 생략하지 않는 5단계 표준
바이브코딩으로 누구나 앱을 배포하는 시대. 하지만 런칭 후 '사고'를 막는 건 코딩 실력이 아니라 엔지니어링 표준입니다.
단순히 Vercel 배포 버튼만 누르고 계신가요? 현업에서 서비스 배포 전, 대형 사고 방지를 위해 반드시 확인하는 5단계 안전장치를 공개합니다.
1단계: 가시성 확보 (Logging & Monitoring)
관련 포스트
AI Engineering
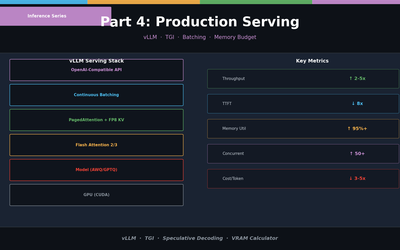
LLM 추론 최적화 Part 4 — 프로덕션 서빙
vLLM과 TGI로 프로덕션 배포. Continuous Batching, Speculative Decoding, 메모리 버짓 설계, 처리량 벤치마크.
AI Engineering
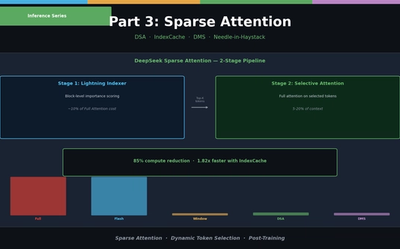
LLM 추론 최적�� Part 3 — Sparse Attention 실전
Sliding Window, Sink Attention, DeepSeek DSA, IndexCache, Nvidia DMS. 동적 토큰 선별부터 Needle-in-Haystack 평가까지.
AI Engineering
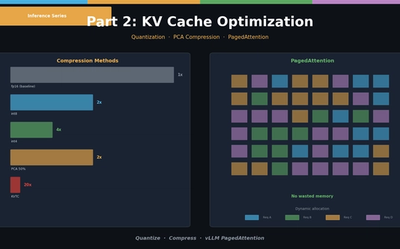
LLM 추론 최적화 Part 2 — KV Cache 최적화
KV Cache 양자화(int8/int4), PCA 압축(KVTC), PagedAttention(vLLM). 실전 메모리 절감 코드와 시나리오별 설정 가이드.